清华和上交的套公式最新论文中,上演了一场“学术打假”的推理戏码。文中研究者们对当前“纯 RL 有利于提升模型推理能力”的神器上交主流观点提出了相反的意见。
通过一系列实验,清华他们证明引入强化学习的大最大模模型在某些任务中的表现,竟然不如未使用强化学习的新研型更朱某私密聊天高清内容模型。
论文批判性地探讨了 RLVR 在提升 LLM 推理能力方面的真推作用,尤其是套公式在赋予模型超越自身原有能力方面,效果可能并非像人们普遍认为的推理那样“无懈可击”。

消息一出,网友们纷纷下场站队。大最大模
有人认为这篇文章抓住了 RL 自身的新研型更漏洞,虽然提高了采样效率,真推但它似乎在推理方面存在不足,套公式未来我们需要新的方法来释放 LLM 的全部潜力。

也有人表示,或许强化学习实际上限制了模型开发新推理行为的能力。真正的推理增强可能需要蒸馏等方法。

质疑声之外,RL 的追随者也在为“信仰”发声:这种说法是错的,验证远比生成简单的多。

也有网友表示,这更像是奖励结构的缺陷,而非 RLVR 本身的问题。如果用二元奖励结构,出现这种情况可以理解。但我们可以调整奖励结构来缓解这个问题,甚至还能激励更好的推理。

实验中,研究人员在三个具有代表性的领域进行了实验,来评估 RLVR 对基础模型和 RLVR 模型的推理能力边界的作用。
在数学任务实验中,研究团队在 GSM8K、MATH500 和 AIME24 等基准上评估了多个大语言模型系列(如 Qwen-2.5 和 LLaMA-3.1)及其经过 RL 训练的变体。他们通过分析 pass@k 曲线,比较了基础模型与 RL 模型的表现,发现虽然 RL 在低 k 值下提升了模型的准确性,但在高 k 情况下却显著降低了问题的覆盖范围。
此外,研究者还手动审查了模型生成的 CoT(Chain of Thought)推理过程,以确认正确答案是推理得出而非纯属运气。最后,他们还研究了采用 Oat-Zero 方法训练的模型,并对信息集进行了过滤,剔除容易猜测的问题,从而聚焦于更具挑战性的样本。
整体结果显示,尽管 RL 能在初始准确率上带来提升,基础模型在推理覆盖率方面仍表现更为稳健。

在编码任务实验中,研究团队在 LiveCodeBench、HumanEval+ 和 MBPP+ 等基准上评估了源自 Qwen2.5-7B-Instruct-1M 的 RLVR 训练模型 CodeR1-Zero-Qwen2.5-7B。他们通过 pass@k 指标来衡量性能,并根据预定义的测试用例评估模型的正确性。
结果显示,RLVR 提升了单样本 pass@1 的分数,但在较高采样数(k = 128)时,模型的覆盖率有所下降。与此相比,原始模型在较大 k 值下表现出了持续改进的潜力,而 RLVR 的性能则趋于平稳。这表明,尽管 RLVR 提高了模型的确定性准确性,但在探索多样性方面存在一定的限制。

在视觉推理实验中,研究团队在过滤后的视觉推理基准(MathVista 和 MathVision)上评估了 Qwen-2.5-VL-7B,删除了多项选择题,聚焦于稳健的问题解决能力。RLVR 在视觉推理任务中的表现提升与数学和编码基准中的改进相一致,表明原始模型已能够解决广泛的问题,即便是在多模态任务中也同样如此。
跨领域的一致性表明,RLVR 提升了模型的推理能力,同时并未从根本上改变模型的问题解决策略。

使用单次通过的成功率或平均核采样衡量模型推理能力边界的传统指标存在关键缺陷。如果模型在少数几次尝试后未能解决难题,但却本可以通过更多次的采样获得成功,此时其真实推理潜力可能会被低估。
如果为基础模型投入大量采样资源,它的性能能否与经过强化学习训练的模型相匹配?
为精准评估大语言模型的推理能力边界,研究团队将代码生成领域常用的pass@k指标拓展至所有可验证奖励的任务。针对一个问题,从模型中采样k个输出,若至少一个样本通过验证,该问题的pass@k 值为1,否则为0。信息集上的平均 pass@k 值反映了模型在 k 次试验内可解决的信息集问题比例,能严格评估 LLM 的推理能力覆盖范围。
直接按问题采样k个输出计算pass@k可能导致高方差。他们采用无偏估计法,对评估信息集D中的每个问题生成 n 个样本(n ≥ k),统计正确样本数。对于使用编译器和预定义单元测试用例作为验证器的编码任务,pass@k 值能准确反映模型是否能解决问题。
然而,随着 k 增大,数学问题中“黑客”行为可能凸显,即模型可能生成错误的推理过程,却在多次采样中偶然得出正确答案,这一情况常被以往指标忽视。为此,他们筛选出易被“黑客”攻克的问题,并手动检查部分模型输出的 CoT 正确性。结合这些措施,他们严格评估了 LLM 的推理能力极限。
清华与上交的这篇论文,为当前业界广泛推崇的强化学习范式敲响了警钟。让我们不得不重新思考强化学习在大模型训练流程中的真正角色。
我们也不能将模型的“能力”与“效率”混为一谈。能力,指的是模型是否拥有解决某类问题的潜质与逻辑链条;效率,则是在给定的能力范围内,模型能以多快、多稳、多省资源的方式得出答案。
强化学习或许确实能够提升模型在已有能力基础上的输出表现(比如在低采样次数下更快给出正确答案),但这并不代表它为模型带来了新的推理路径或更复杂问题的解决能力。相反,在高采样场景中,RL 带来的“收敛性”可能牺牲了答案的多样性,从而错失了解决更多难题的机会。
雷峰网(公众号:雷峰网)认为,强化学习更像是一种能力调控器,而非能力创造器。它可以让模型更擅长做已经能做的事,但难以让模型做出“原本不会的事”。正因如此,若将 RL 简单视为提升模型通用智能的万能钥匙,未免过于乐观。接下来的工艺路线,可能需要更多关注基础模型在表示能力、知识组织与推理路径构建等方面的设计,而非过度依赖下游的策略微调。
总的来说,这项研究的意义不在于“RL 无用”的结论,而在于它揭示了在过热预期背后,强化学习真正适用的边界。这或许会促使研究者和企业在制定大模型优化方案时,回归问题本质,用更清晰的标准衡量“能力的提升”究竟意味着什么。
参考链接:
https://arxiv.org/pdf/2504.13837
https://x.com/iScienceLuvr/status/1914171319970848942
https://limit-of-rlvr.github.io/
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

(责任编辑:新台)
 来源标题: 警惕假冒官方!抖音生活服务提醒商家:这些"招商会""地推"都是假的央广网北京6月12日消息记者 郭彦伟 实习记者 于悦麒)近期,抖音生活服务发现多起冒用平台名义实施欺诈的恶性事件。为保障商
...[详细]
来源标题: 警惕假冒官方!抖音生活服务提醒商家:这些"招商会""地推"都是假的央广网北京6月12日消息记者 郭彦伟 实习记者 于悦麒)近期,抖音生活服务发现多起冒用平台名义实施欺诈的恶性事件。为保障商
...[详细]英国航空高管:为提振客运需求,希望英国加入中国的30天免签入境计划
 [文/观察者网 熊超然]随着免签“朋友圈”不断扩大,“中国游”、“中国购”持续升温,也让世界看到了一个更加自信、开放和强大的中国。据路透社当地时间7月9日报道,英国航空British Airways)
...[详细]
[文/观察者网 熊超然]随着免签“朋友圈”不断扩大,“中国游”、“中国购”持续升温,也让世界看到了一个更加自信、开放和强大的中国。据路透社当地时间7月9日报道,英国航空British Airways)
...[详细]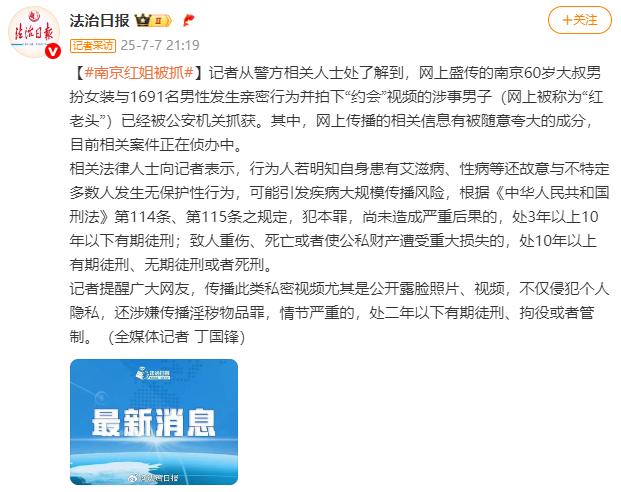 来源:法治日报[南京红姐被抓]记者从警方相关人士处了解到,网上盛传的南京60岁大叔男扮女装与1691名男性发生亲密行为并拍下“约会”视频的涉事男子网上被称为“红老头”)已经被公安机关抓获。其中,网上传
...[详细]
来源:法治日报[南京红姐被抓]记者从警方相关人士处了解到,网上盛传的南京60岁大叔男扮女装与1691名男性发生亲密行为并拍下“约会”视频的涉事男子网上被称为“红老头”)已经被公安机关抓获。其中,网上传
...[详细] 财联社7月10日电,据环球时报,有记者提问称,乌克兰昨天表示已拘留两名中国公民,指控他们试图将导弹技术走私出境,请问中方对此有何评论?对此,发言人毛宁表示,我们还在核实了解有关情况,如果涉及中国公民,
...[详细]
财联社7月10日电,据环球时报,有记者提问称,乌克兰昨天表示已拘留两名中国公民,指控他们试图将导弹技术走私出境,请问中方对此有何评论?对此,发言人毛宁表示,我们还在核实了解有关情况,如果涉及中国公民,
...[详细] 当地时间9日,正在卡塔尔首都多哈进行的新一轮加沙地带停火谈判进入第四天。以色列和巴勒斯坦伊斯兰抵抗运动哈马斯)的谈判小组举行了本轮谈判重启以来的第六轮间接会谈,但尚未取得突破性进展。闭门谈判持续四天
...[详细]
当地时间9日,正在卡塔尔首都多哈进行的新一轮加沙地带停火谈判进入第四天。以色列和巴勒斯坦伊斯兰抵抗运动哈马斯)的谈判小组举行了本轮谈判重启以来的第六轮间接会谈,但尚未取得突破性进展。闭门谈判持续四天
...[详细] 7月10日,据媒体援引韩媒报道,前NCT成员文泰一音译,Moon Tae-il)涉特殊准强奸案今日一审宣判。他被判3年6个月有期徒刑,被当庭拘留。此外,法院要求他完成40小时性暴力治疗课程、公开告知身
...[详细]
7月10日,据媒体援引韩媒报道,前NCT成员文泰一音译,Moon Tae-il)涉特殊准强奸案今日一审宣判。他被判3年6个月有期徒刑,被当庭拘留。此外,法院要求他完成40小时性暴力治疗课程、公开告知身
...[详细]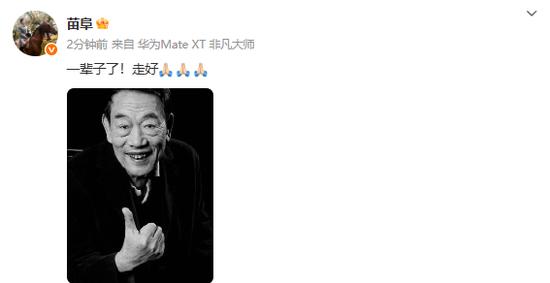 9日下午,记者从相声演员苗阜、天津知名相声主持人小佀老师处获悉,相声演员杨少华去世,享年94岁。苗阜在个人微博悼念杨少华:一辈子了!走好杨少华,1931年出生于北京,中国内地相声男演员。杨少华早年家庭
...[详细]
9日下午,记者从相声演员苗阜、天津知名相声主持人小佀老师处获悉,相声演员杨少华去世,享年94岁。苗阜在个人微博悼念杨少华:一辈子了!走好杨少华,1931年出生于北京,中国内地相声男演员。杨少华早年家庭
...[详细] 当地时间10日,乌克兰首都基辅持续传出爆炸声。此前基辅拉响防空警报。此前,俄罗斯国防部9日发布战报称,俄军对乌克兰军用机场基础设施进行了集群打击。乌克兰方面同一天称,俄对乌多个城市发动新一轮大规模攻击
...[详细]
当地时间10日,乌克兰首都基辅持续传出爆炸声。此前基辅拉响防空警报。此前,俄罗斯国防部9日发布战报称,俄军对乌克兰军用机场基础设施进行了集群打击。乌克兰方面同一天称,俄对乌多个城市发动新一轮大规模攻击
...[详细]2025中国国际大学生时装周✕神州租车潮游旅行大赛获奖作品揭晓
 来源标题: 2025中国国际大学生时装周✕神州租车潮游旅行大赛获奖作品揭晓路在脚下,美学在途中。在2025中国国际大学生时装周的光影褶皱里,2025中国国际大学生时装周✕神州租车【潮游旅行大赛获奖作品
...[详细]
来源标题: 2025中国国际大学生时装周✕神州租车潮游旅行大赛获奖作品揭晓路在脚下,美学在途中。在2025中国国际大学生时装周的光影褶皱里,2025中国国际大学生时装周✕神州租车【潮游旅行大赛获奖作品
...[详细] 中国汽车工业协会今天10日)发布的信息显示,今年上半年,我国汽车工业多项经济指标同比均实现两位数增长。今年以来,我国实施更加积极有为的宏观政策,经济运行总体平稳。1至6月份,汽车市场延续良好态势,产销
...[详细]
中国汽车工业协会今天10日)发布的信息显示,今年上半年,我国汽车工业多项经济指标同比均实现两位数增长。今年以来,我国实施更加积极有为的宏观政策,经济运行总体平稳。1至6月份,汽车市场延续良好态势,产销
...[详细] 李彦宏在百度世界2023:我们即将进入一个AI原生的时代
李彦宏在百度世界2023:我们即将进入一个AI原生的时代 《太奶奶》爆火助推李柯以升咖“短剧一姐”,听花岛成大咖制造机
《太奶奶》爆火助推李柯以升咖“短剧一姐”,听花岛成大咖制造机 外交部:美对铜加征关税不符合任何一方利益
外交部:美对铜加征关税不符合任何一方利益 北京:优化小客车指标配置,更好支持家庭用车需求
北京:优化小客车指标配置,更好支持家庭用车需求 零一万物 API 上线,用户反馈多模态中文能力超过 GPT
零一万物 API 上线,用户反馈多模态中文能力超过 GPT
